
Llama-2-Chat which is optimized for dialogue has shown similar performance to popular closed-source models like ChatGPT and PaLM. LLaMA 20 was released last week setting the benchmark for the best open source OS language model Heres a guide on how you can. Here are some quick facts about Llama-2 Fine-tuning allows you to train Llama-2 on your proprietary dataset to perform better at specific tasks. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7. Fine-tuning large language models in practice In this tutorial we show how to fine-tune the powerful LLaMA 2 model with Paperspaces..
Medium
Open source free for research and commercial use Were unlocking the power of these large language models. Llama 2 The next generation of our open source large language model available for free for research and. Yes we will publish benchmarks alongside the release If there are particular benchmarks partners are. Llama is the next generation of our open source large language model available for free for research and commercial. Today were introducing the availability of Llama 2 the next generation of our open source. Llama 2 the next generation of our open-source large language model..
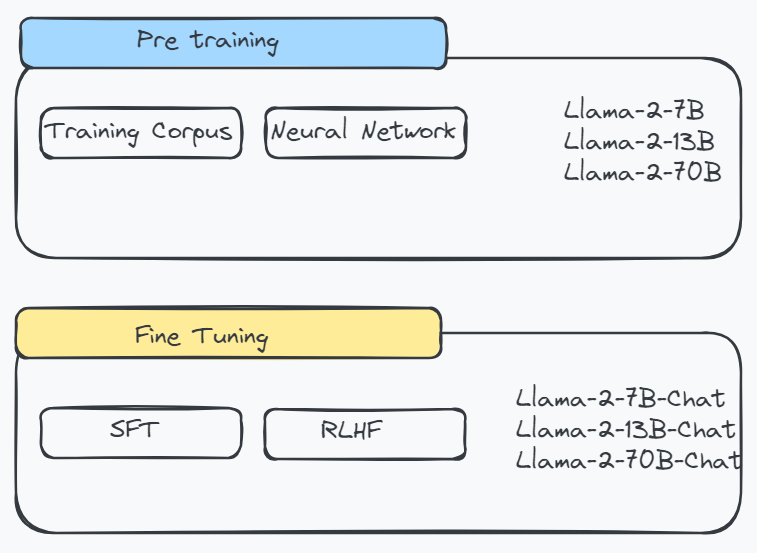
This dataset contains chunked extracts of 300 tokens from papers related to and including the Llama 2 research paper Related papers were identified by following a trail of references. Open Foundation and Fine-Tuned Chat Models In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging. NORB is completely trained within fve epochs Test error rates on MNIST drop to 242 097 and 048 after 1 3 and 17 epochs respectively. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Open Foundation and Fine-Tuned Chat Models Published on Jul 18 2023 Featured in Daily Papers on Jul 18 2023 Authors Hugo Touvron Louis Martin..
Medium
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models Unlike OpenAI papers where you have to deduce it. Jose Nicholas Francisco Published on 082323 Updated on 101123 Llama 1 vs Metas Genius Breakthrough in AI Architecture Research Paper Breakdown First. 6 min read Oct 8 2023 Llama 2 is a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters On the series of helpfulness and safety..
Komentar